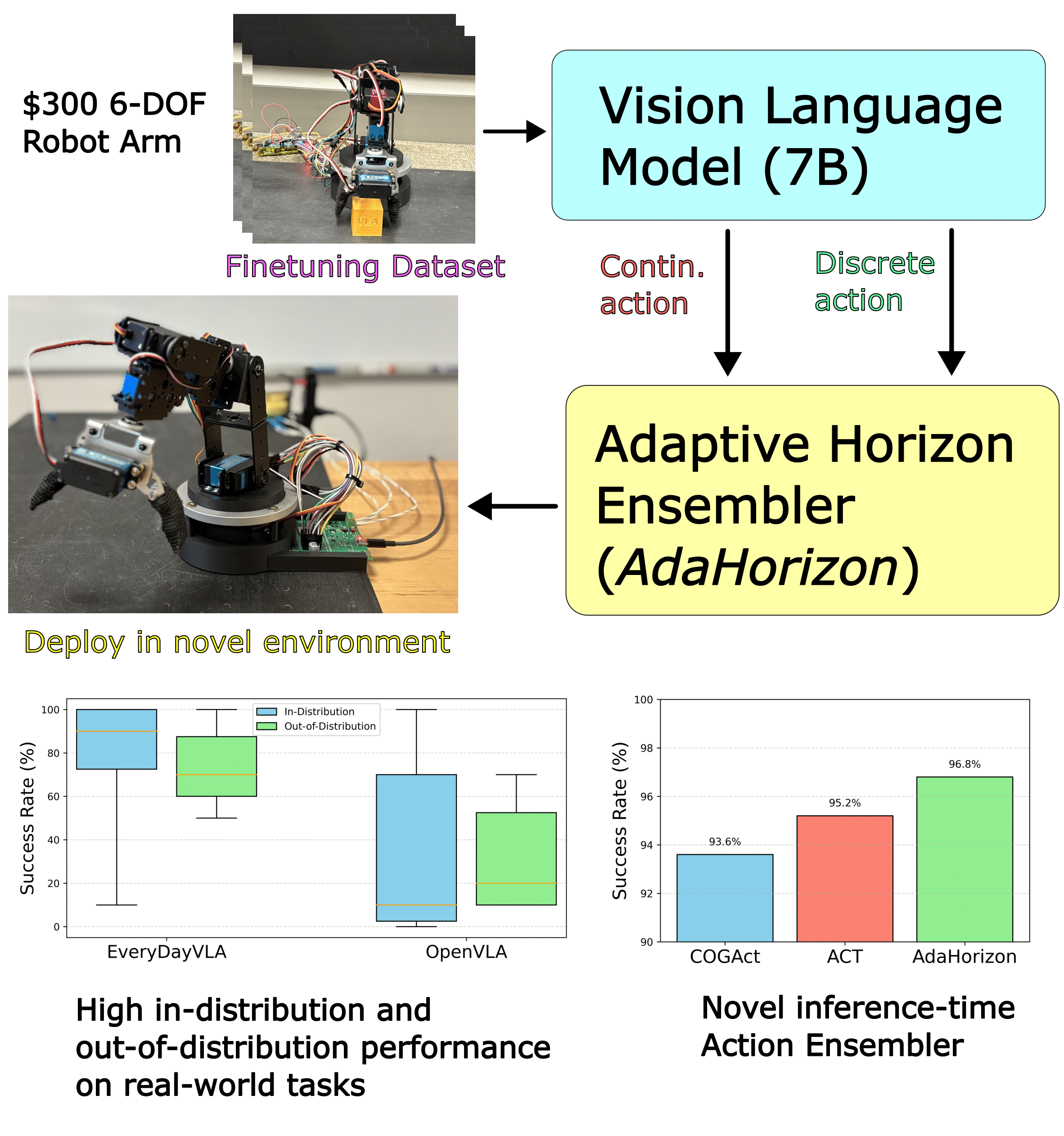
EveryDayVLA
leverages VLA models to plan robotic actions in real-time.
EveryDayVLA proposes three distinct contributions:
(1) Collaborative training with adaptive horizon control (AdaHorizon).
(2) A low-cost, integrated 6-DOF manipulator.
(3) An automated data-collection pipeline and public dataset used to train our robot.
Abstract
While Vision–Language–Action (VLA) models map visual inputs and language instructions directly to robot
actions, they often rely on costly hardware and struggle in novel or cluttered scenes. We introduce
EverydayVLA, a 6-DOF manipulator that can be assembled for $300, capable of modest payloads and
workspaces. A single unified model jointly outputs discrete and continuous actions, and our
adaptive-horizon ensembler monitors motion uncertainty to trigger on-the-fly replanning for safe,
reliable operation. On LIBERO, EverydayVLA matches state-of-the-art success rates, and in real-world
tests it outperforms prior methods by 49% in-distribution and 34.9% out-of-distribution. By combining a
state-of-the-art VLA with cost-effective hardware, EverydayVLA democratizes access to a robotic
foundation model, and paves the way for economical use in homes and research labs alike.
Hardware Experiments
We tested our model, EverydayVLA, against OpenVLA and OpenVLA-OFT trained on our dataset.
In-distribution Tasks
We tested the models on objects seen in training: block, ball, and rock.
EveryDayVLA (ours)
Move the block away from the robot
✅
OpenVLA
Move the block away from the robot
✅
OpenVLA-OFT
Move the block away from the robot
❌
EveryDayVLA (ours)
Move the ball away from the robot
✅
OpenVLA
Move the ball away from the robot
❌
OpenVLA-OFT
Move the block ball from the robot
✅
EveryDayVLA (ours)
Move the rock away from the robot
✅
OpenVLA
Move the rock away from the robot
❌
OpenVLA-OFT
Move the rock away from the robot
❌
Additionally, we tested the models on other actions seen in training.
EveryDayVLA (ours)
Move the block to the left
✅
OpenVLA
Move the block to the left
⚠️
OpenVLA-OFT
Move the block to the left
❌
Out-of-Distribution Tasks
We also tested the models on objects not seen in training: a blue flask and a creeper keychain.
EveryDayVLA (ours)
Move the flask away from the robot
✅
OpenVLA
Move the flask away from the robot
❌
OpenVLA-OFT
Move the flask away from the robot
✅
EveryDayVLA (ours)
Move the green toy away from the robot
✅
OpenVLA
Move the green toy away from the robot
⚠️
OpenVLA-OFT
Move the green toy away from the robot
⚠️
Distractions
We tested with static and dynamic distractions
EveryDayVLA (ours)
Move the block away from the robot
✅
OpenVLA
Move the block away from the robot
✅
OpenVLA-OFT
Move the block away from the robot
❌
EveryDayVLA (ours)
Move the block away from the robot
 EveryDayVLA
leverages VLA models to plan robotic actions in real-time.
EveryDayVLA proposes three distinct contributions:
(1) Collaborative training with adaptive horizon control (AdaHorizon).
(2) A low-cost, integrated 6-DOF manipulator.
(3) An automated data-collection pipeline and public dataset used to train our robot.
EveryDayVLA
leverages VLA models to plan robotic actions in real-time.
EveryDayVLA proposes three distinct contributions:
(1) Collaborative training with adaptive horizon control (AdaHorizon).
(2) A low-cost, integrated 6-DOF manipulator.
(3) An automated data-collection pipeline and public dataset used to train our robot.